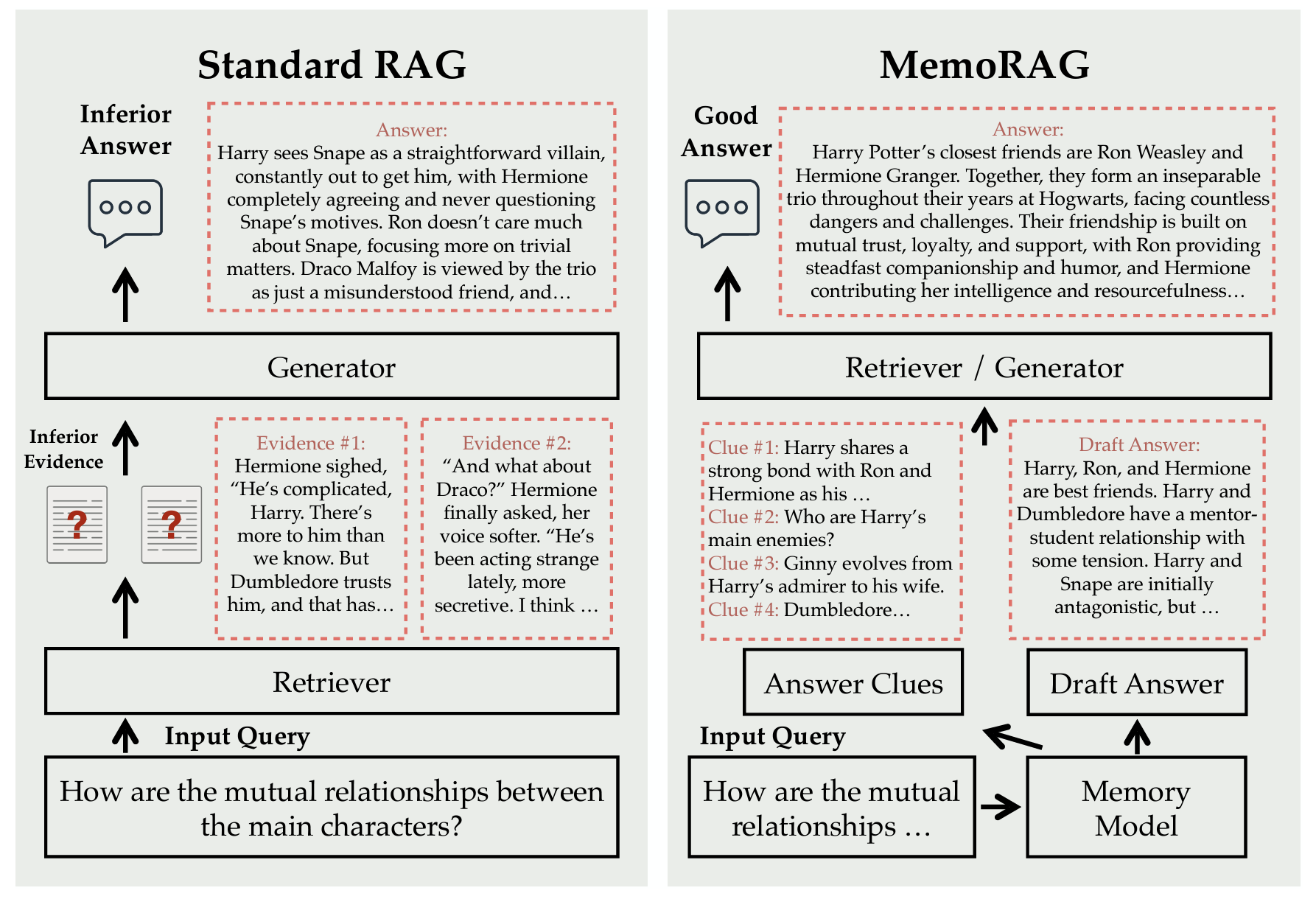
Claude Code 上下文管理机制详解
Generated by Claude Code.
目录
上下文窗口基础 上下文中都装了什么 自动压缩机制 (Auto-Compaction) CLAUDE.md 的加载与持久性 文件读取与工具结果管理 子代理 (Subagent) 的上下文隔离 持久化记忆系统 (Auto Memory) Token 计数与预算管理 会话管理与检查点 其他优化机制 最佳实践 深入实现:Memory 机制的内部工作原理
1. 上下文窗口基础 Claude Code 使用底层 Claude 模型的上下文窗口限制:
模型
标准上下文窗口
扩展选项
Opus 4.6
~200K tokens
1M tokens (opus[1m])
Sonnet 4.6
~200K tokens
1M tokens (sonnet[1m])
Haiku 4.5
较小窗口
无扩展选项
上下文窗口是一个共享资源 ,所有内容——对话历史、文件内容、系统提示、工具定义——都在同一个窗口内竞争空间。没有独立的 “token 预算” 设置,Claude Code 通过自动机制管理上下文使用。
2. 上下文中都装了什么 一次 API 请求中,上下文窗口包含以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌─────────────────────────────────────────────┐ │ System Prompt (系统提示) │ ← 每次请求都包含 ├─────────────────────────────────────────────┤ │ CLAUDE.md 内容 (所有层级) │ ← 每次请求都包含,压缩后重新注入 ├─────────────────────────────────────────────┤ │ Auto Memory (MEMORY.md 前 200 行) │ ← 每次请求都包含 ├─────────────────────────────────────────────┤ │ Skills 描述 (所有已注册的 skill 的简短描述) │ ← 每次请求都包含 ├─────────────────────────────────────────────┤ │ MCP Server 工具定义 │ ← 每次请求都包含 ├─────────────────────────────────────────────┤ │ 对话历史 │ │ ├── 用户消息 1 │ │ ├── Claude 回复 1 (含工具调用与结果) │ │ ├── 用户消息 2 │ │ ├── Claude 回复 2 ... │ │ └── ... │ ← 累积增长,触发压缩 ├─────────────────────────────────────────────┤ │ 当前请求的 Thinking tokens (输出侧) │ ← 按 effort 级别动态分配 └─────────────────────────────────────────────┘
关键观察 :CLAUDE.md、Memory、Skills 描述、MCP 工具定义在每一次 请求中都会发送,这是固定的上下文开销。对话历史是唯一持续增长的部分。
3. 自动压缩机制 (Auto-Compaction) 这是 Claude Code 上下文管理的核心机制 ——当对话越来越长、上下文窗口快要被填满时,Claude Code 如何在不丢失关键信息的前提下”腾出空间”继续工作。
3.1 触发条件 默认触发阈值 :当上下文使用量达到容量的约 83.5% 时自动触发。对于 200K token 的窗口,这大约是 ~167K tokens。
为什么不是 100%?因为 Claude Code 需要预留约 33K-45K token 的缓冲区 ,用于:压缩过程本身的 token 开销、生成回复的输出 token 空间、以及压缩后重新注入 CLAUDE.md 等固定内容。
阈值配置 :
1 2 3 4 5 CLAUDE_AUTOCOMPACT_PCT_OVERRIDE=50 claude CLAUDE_AUTOCOMPACT_PCT_OVERRIDE=80
手动触发 :
1 2 3 /compact /compact focus on auth refactoring /compact 保留数据库 schema 变更和 API 测试结果
一个实际的触发时间线示例 :
1 2 3 4 5 6 7 8 9 10 200K token 窗口: 0K ─────── 50K ─────── 100K ─────── 150K ─────── 167K ─── 200K │ │ │ │ │ │ 会话开始 正常对话 读了几个大文件 上下文开始紧张 ⚡触发压缩 窗口上限 │ Claude Code 自动介入 ↓ 压缩后回到 ~80K-100K 继续工作...
3.2 压缩的完整生命周期 压缩是一个多步骤的过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ┌─────────────────────────────────────────────────────────┐ │ Phase 0: 检测 │ │ 监控 token 使用量 → 达到 83.5% → 准备压缩 │ ├─────────────────────────────────────────────────────────┤ │ Phase 1: PreCompact Hooks │ │ 触发 PreCompact 钩子(如果配置了的话) │ │ → 可以用来记录日志、发送通知等 │ │ → 不能阻止压缩 │ ├─────────────────────────────────────────────────────────┤ │ Phase 2: 工具输出清理 │ │ 从活跃上下文中移除较旧的工具调用结果: │ │ ├── 旧的 Bash 命令输出 │ │ ├── 旧的 Read 文件内容 │ │ ├── 旧的 Grep/Glob 搜索结果 │ │ └── 旧的 API 调用返回值 │ │ 保留最近的工具结果(供当前推理使用) │ │ 注意:这些内容始终保留在 transcript 文件中(见 3.9 节) │ ├─────────────────────────────────────────────────────────┤ │ Phase 3: 对话历史摘要化 │ │ 使用当前会话的同一模型(如 Opus/Sonnet)生成摘要: │ │ ├── 输入:整个对话历史 │ │ ├── 保留:用户请求、代码变更、架构决策、关键错误信息 │ │ ├── 压缩:中间探索过程、讨论细节、已解决的问题 │ │ └── 丢弃:冗长的工具输出、重复的尝试过程 │ ├─────────────────────────────────────────────────────────┤ │ Phase 4: 上下文重建 │ │ ├── 从磁盘重新读取 CLAUDE.md(所有层级) │ │ ├── 重新加载 MEMORY.md(前 200 行) │ │ ├── 重新加载 .claude/rules/ 文件 │ │ ├── 恢复任务列表 │ │ └── 将摘要 + 重新注入的内容组合为新的上下文 │ ├─────────────────────────────────────────────────────────┤ │ Phase 5: PostCompact Hooks │ │ 触发 PostCompact 钩子 │ │ → 可以重新注入关键上下文 │ │ → 可以记录压缩事件 │ ├─────────────────────────────────────────────────────────┤ │ Phase 6: 继续对话 │ │ Claude 从压缩后的摘要继续工作 │ │ transcript 文件记录 compact_boundary 标记 │ └─────────────────────────────────────────────────────────┘
压缩日志记录 :每次压缩在 transcript 文件中留下标记:
1 2 3 4 5 6 7 8 { "type" : "system" , "subtype" : "compact_boundary" , "compactMetadata" : { "trigger" : "auto" , "preTokens" : 167189 } }
3.3 压缩后保留什么——详细分析
内容类型
压缩后状态
说明
CLAUDE.md
完全保留 从磁盘重新读取,不依赖对话历史
Auto Memory (MEMORY.md)
完全保留 重新加载前 200 行
.claude/rules/
完全保留 重新加载
代码编辑记录
保留 文件变更和 diff 被保留在摘要中
用户核心请求
保留 “实现 X 功能” 这类顶层任务被保留
关键决策
保留 “我们决定用 PostgreSQL 而不是 MongoDB”
关键错误信息
保留 正在调试的核心错误信息
详细对话过程
可能丢失 中间讨论、探索性对话被压缩
早期口头指令
很可能丢失 第 3 轮对话说的 “记住用 pnpm” 可能消失
旧工具输出
从活跃上下文移除 在 transcript 文件中完整保留,但 Claude 无法自动找回(见 3.9)
中间探索步骤
丢失 “我试了 A 方案不行,又试了 B” 的细节
一个具体例子 ——压缩前后的对话变化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 压缩前的对话历史(简化示意): ───────────────────────────────── Turn 1: 用户: "帮我重构 auth 模块,用 JWT 替换 session" Turn 2: Claude: 读取了 src/auth/session.js (500行) Turn 3: Claude: 读取了 src/auth/middleware.js (300行) Turn 4: Claude: 读取了 src/models/user.js (200行) Turn 5: 用户: "对了,所有 token 过期时间设为 24 小时" Turn 6: Claude: 分析了三个文件,提出了重构方案 Turn 7: Claude: 尝试方案 A —— 直接替换,发现有循环依赖 Turn 8: Claude: 尝试方案 B —— 先抽取接口,成功 Turn 9: Claude: 修改了 session.js,编写了 jwt.js Turn 10: Claude: 运行测试 —— 3 个失败 Turn 11: Claude: 修复了测试,2 个仍然失败 Turn 12: Claude: 发现是 mock 数据过期,修复了 Turn 13: 用户: "顺便加个 refresh token 机制" 压缩后的摘要(大致内容): ───────────────────────────────── 摘要: 用户要求重构 auth 模块,用 JWT 替换 session。 已完成: - 分析了 session.js, middleware.js, user.js - 采用方案 B(先抽取接口)成功重构 - 创建了 jwt.js,修改了 session.js - 测试已全部通过(修复了 mock 数据问题) 当前任务:添加 refresh token 机制 关键约束:token 过期时间 24 小时 [CLAUDE.md 和 MEMORY.md 从磁盘重新注入] 注意:从活跃上下文中丢失的信息: - Turn 2-4 的文件完整内容(500+300+200 行)不再在活跃上下文中 (仍在 transcript 文件中,但 Claude 无法自动找回;需要时会重新 Read 源文件) - Turn 7 方案 A 失败的具体细节丢失 - Turn 10-12 的测试调试细节丢失 - Turn 5 的 "24小时" 指令可能被保留在摘要中,但不确定 如果 "24小时" 写在 CLAUDE.md 中: → 100% 保留,因为 CLAUDE.md 从磁盘重新读取
3.4 自定义压缩行为 有三种方式控制压缩时保留什么:
方式 1: CLAUDE.md 中的 Compact Instructions 在 CLAUDE.md 中添加专门的压缩指导节:
1 2 3 4 5 6 7 8 # Compact Instructions When compacting, prioritize preserving: - All API endpoint signatures and their test status- Database schema change decisions and migration order- Authentication flow architecture decisions- Current sprint goal: v2 API migration- Package manager: always use pnpm, never npm
这段内容本身在 CLAUDE.md 中,压缩后会从磁盘重新读取,所以 Claude 在每次压缩后都能看到这些指导。
方式 2: /compact 命令的焦点参数 1 2 3 /compact focus on the JWT implementation and refresh token mechanism /compact 保留所有关于数据库迁移的决策和测试结果 /compact keep error messages and stack traces from the auth module debugging
这适合一次性的、针对当前工作的压缩指导。
方式 3: PostCompact Hook 重新注入上下文 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 { "hooks" : { "PostCompact" : [ { "hooks" : [ { "type" : "command" , "command" : "echo 'REMINDER: We are working on v2 API migration. Use pnpm. All endpoints need OpenAPI docs. Current focus: auth module JWT refactor.'" } ] } ] } }
Hook 输出的内容会作为系统消息注入到压缩后的上下文中。更复杂的用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "hooks" : { "PostCompact" : [ { "hooks" : [ { "type" : "command" , "command" : "cat .claude/post-compact-context.md" } ] } ] } }
其中 .claude/post-compact-context.md 可以是一个维护好的文件,包含压缩后需要重新注入的所有关键上下文。
3.5 PreCompact 和 PostCompact Hooks 详解 Hook 接收的数据 :
1 2 3 4 5 6 { "session_id" : "abc123" , "cwd" : "/path/to/project" , "hook_event_name" : "PreCompact" , "matcher_value" : "auto" }
PreCompact Hook 示例 ——压缩前保存关键上下文到文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "hooks" : { "PreCompact" : [ { "hooks" : [ { "type" : "command" , "command" : "echo \"[$(date)] Compaction triggered\" >> ~/.claude/compaction.log" } ] } ] } }
PostCompact Hook 示例 ——压缩后重新注入上下文:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "hooks" : { "PostCompact" : [ { "hooks" : [ { "type" : "command" , "command" : "echo 'Current sprint: auth refactor. Use Bun not npm. Focus on /api/v2/ directory. TypeScript strict mode.'" } ] } ] } }
注意:PreCompact 不能阻止压缩(返回值被忽略),只用于副作用。
3.6 多次压缩与质量退化 在长会话中,压缩可能触发多次。每次压缩都是在上一次的摘要基础上 再次摘要:
1 2 3 4 5 6 7 8 9 10 11 第 1 次压缩: 原始对话 → 摘要 1(保留约 95% 语义内容) ↓ 继续对话,上下文再次填满 ↓ 第 2 次压缩: 摘要 1 + 新对话 → 摘要 2(开始丢失一些细节) ↓ 继续对话... ↓ 第 3 次压缩: 摘要 2 + 新对话 → 摘要 3(细节进一步模糊) ↓ 第 4+ 次压缩: 上下文变得越来越高层和抽象
质量退化表现 :
第 1 次压缩:几乎无感知的信息丢失
第 2-3 次压缩:一些具体的函数名、行号、错误细节可能丢失
第 4+ 次压缩:可能会重新探索之前已经解决的问题
缓解策略 :
关键信息写入 CLAUDE.md(不受压缩次数影响)
使用 PostCompact Hook 每次压缩后重新注入
对高容量工作(搜索、测试)使用子代理隔离
长会话考虑使用 1M token 扩展窗口(opus[1m])减少压缩频率
3.7 /compact 与 /clear 的区别
维度
/compact/clear
做了什么 摘要化对话历史,压缩上下文
完全清空对话历史,重新开始
上下文保留 保留摘要后的上下文
归零,全新窗口
CLAUDE.md 从磁盘重新读取
从磁盘重新读取
Auto Memory 保留(独立存储)
保留(独立存储)
token 释放量 中等(压缩后仍有摘要)
最大(完全清空)
适用场景 长会话需要继续工作
切换到完全不相关的任务
可逆性 transcript 保留在磁盘上
可通过 --continue 恢复旧会话
选择指南 :
1 2 3 4 5 6 7 8 9 10 11 你在做一个持续的任务,上下文快满了? → /compact(保留工作上下文) 你要开始一个完全不同的任务? → /clear(干净的开始) 你在做一个任务,但感觉 Claude "忘了"早期的指令? → 把关键指令写进 CLAUDE.md,然后 /compact 上下文被"污染"了(大量无关的工具输出)? → /compact(清理工具输出,保留对话精华)
3.8 配置一览
配置项
类型
说明
CLAUDE_AUTOCOMPACT_PCT_OVERRIDE环境变量
自定义触发阈值(只能调低)
CLAUDE.md # Compact Instructions
文件内容
引导压缩时保留什么
hooks.PreCompactsettings.json
压缩前执行的脚本
hooks.PostCompactsettings.json
压缩后执行的脚本(可注入上下文)
/compact <指令>命令
手动触发带焦点的压缩
3.9 Transcript 文件:压缩背后的真正存储机制 这一节澄清一个容易误解的关键问题:压缩时数据到底存到了哪里?
核心概念:活跃上下文 vs Transcript 文件 Claude Code 有两层数据存储,理解它们的区别是理解压缩机制的关键:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌─────────────────────────────────────────────────────────────┐ │ │ │ 层 1: 活跃上下文 (Active Context) │ │ ════════════════════════════════ │ │ · 每次 API 请求发送给 Claude 模型的内容 │ │ · 存在于内存中 │ │ · 受上下文窗口大小限制(200K / 1M tokens) │ │ · 压缩直接作用于这一层 —— │ │ 旧工具输出被移除,对话被摘要化 │ │ │ ├─────────────────────────────────────────────────────────────┤ │ │ │ 层 2: Transcript 文件 (Transcript File) │ │ ════════════════════════════════════ │ │ · 持久化到磁盘的完整会话记录 │ │ · 路径: ~/.claude/projects/<项目>/sessions/<会话ID>.jsonl │ │ · JSONL 格式(每行一个 JSON 对象) │ │ · Append-only(只追加,从不修改或删除已有内容) │ │ · 不受上下文窗口大小限制 │ │ · 压缩不会修改这一层 —— 只会追加一条 compact_boundary 记录 │ │ │ └─────────────────────────────────────────────────────────────┘
关键事实 :
工具输出从对话开始就在实时写入 transcript 文件 ——不是压缩时才”存到磁盘”的压缩从不修改或删除 transcript 文件中的任何内容 ——它只在文件末尾追加一条 compact_boundary 记录压缩只影响活跃上下文 (发送给 API 的内容),不影响磁盘上的完整记录
Transcript 文件的结构 1 2 3 4 5 文件位置: ~/.claude/projects/<项目标识>/sessions/<会话ID>.jsonl 此外还有一个索引文件: ~/.claude/projects/<项目标识>/sessions-index.json (包含会话摘要、消息数、分支名、时间戳等元数据)
Transcript 文件是 JSONL(JSON Lines)格式,每一行是一个独立的 JSON 对象:
1 2 3 4 5 6 7 {"type":"user_message","timestamp":"2026-03-26T10:00:00Z","content":"帮我看 auth 模块"} {"type":"tool_use","timestamp":"2026-03-26T10:00:01Z","tool":"Read","input":{"file_path":"src/auth/login.js"}} {"type":"tool_result","timestamp":"2026-03-26T10:00:02Z","content":"[500行代码的完整内容...]"} {"type":"assistant_message","timestamp":"2026-03-26T10:00:05Z","content":"这个文件实现了..."} ... {"type":"system","subtype":"compact_boundary","compactMetadata":{"trigger":"auto","preTokens":167189},"summary":"用户要求分析auth模块..."} ...(压缩后的新对话继续追加)
压缩前后,磁盘上发生了什么 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 压缩前: transcript.jsonl (磁盘): Line 1: user_message "帮我看 auth 模块" Line 2: tool_use Read("src/auth/login.js") Line 3: tool_result [500行代码] ← 完整保存 Line 4: tool_use Bash("npm test") Line 5: tool_result [200行测试输出] ← 完整保存 Line 6: assistant_message "分析结果..." ... Line 50: (当前最新消息) 活跃上下文 (内存/API): 包含 Line 1-50 的全部内容 → 约 167K tokens ═══════════════ 触发压缩 ═══════════════ 压缩后: transcript.jsonl (磁盘): Line 1: user_message "帮我看 auth 模块" ← 未修改! Line 2: tool_use Read("src/auth/login.js") ← 未修改! Line 3: tool_result [500行代码] ← 未修改!仍完整保留 Line 4: tool_use Bash("npm test") ← 未修改! Line 5: tool_result [200行测试输出] ← 未修改!仍完整保留 Line 6: assistant_message "分析结果..." ← 未修改! ... Line 50: (之前的最新消息) ← 未修改! Line 51: compact_boundary {摘要 + 元数据} ← 新追加! Line 52: (压缩后新的对话消息) ← 新追加 活跃上下文 (内存/API): CLAUDE.md (重新读取) + MEMORY.md (重新读取) + 摘要 + 最近的消息 → 约 80K tokens(大幅缩减)
压缩后能否找回旧的工具输出?
方式
可行性
说明
Claude 自动找回
不能 Claude 没有内置机制从 transcript 中提取旧的工具结果
Claude 用 Read 读 transcript 文件
理论上可以,实践中不实用 JSONL 格式不便于定位特定工具输出,且文件可能很大
Claude 重新读取源文件
可以 最实用的方式——直接重新 Read 原始文件
Claude 重新运行命令
可以 重新执行 Bash 命令获取新的输出
人类手动查看 transcript
可以 用 jq 等工具解析 JSONL 文件
通过 --continue / --resume 恢复会话
部分 加载 transcript 但 API 只发送压缩后的版本
实用结论 :
1 2 3 4 5 6 7 8 9 10 压缩后 Claude 如果需要之前读过的文件内容: ✅ 重新调用 Read 工具读取源文件(最简单可靠) ✅ 重新运行命令获取输出 ❌ 无法自动从 transcript 中提取旧结果 压缩后你(人类)想查看之前的完整对话: ✅ 直接查看 transcript 文件 cat ~/.claude/projects/.../sessions/<id>.jsonl | jq '.' ✅ 使用社区工具浏览 transcript (如 withLinda/claude-JSONL-browser, daaain/claude-code-log)
这是一个已知的设计限制 (参见 GitHub issue #27242):压缩后没有实用的内置机制--continue / --resume)和人类审查,而不是 Claude 自己的上下文回溯。
子代理的 Transcript 子代理也有独立的 transcript 文件:
1 ~/.claude/projects/<项目>/sessions/<会话ID>/subagents/agent-<agentId>.jsonl
主会话压缩时,子代理的 transcript 完全不受影响 。通过 SendMessage 恢复子代理时,子代理从自己的 transcript 加载完整历史。
Transcript vs Auto Memory vs CLAUDE.md——三种持久化机制对比 Claude Code 有三种将信息持久化到磁盘的机制,它们的角色完全不同:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Transcript Auto Memory CLAUDE.md ────────── ─────────── ───────── 类比 监控录像 笔记本 规章制度 谁写入 系统自动 Claude 主动 人类手动 写什么 原始数据全量 提炼后的知识 规则和指令 (每条消息、每次 ("用户偏好 pnpm" ("所有 API 必须 工具调用的完整 "测试不要 mock") 有 OpenAPI 注释") 输入和输出) Claude 能用吗 基本不能 主动使用 主动遵循 (JSONL 格式, (MEMORY.md 前 200 行 (全部内容每次 无内置提取机制) 每次请求自动注入) 请求都注入) 作用域 单个会话 跨会话 (项目级) 跨会话 (项目/用户级) (每个 session (同项目所有 session (可入 git, 一个文件) 共享) 跨机器同步) 压缩后 不受影响 MEMORY.md 重新注入 从磁盘重新读取 (但 Claude 看不到) (前 200 行) (全部内容) 存储路径 sessions/<id>.jsonl memory/MEMORY.md 项目根/CLAUDE.md + 主题文件 + .claude/rules/
它们如何协作的例子 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 一次长会话中: 1. Claude 运行 npm test,输出 200 行日志,发现 mock 导致测试误通过 → Transcript: 记录完整的 200 行日志和所有对话 → 活跃上下文: 200 行日志占用上下文空间 2. 触发压缩 → Transcript: 追加 compact_boundary,原始日志不变 → 活跃上下文: 200 行日志被移除,对话被摘要化 → Claude 如果需要日志,必须重新运行 npm test 3. Claude 发现这是一个值得跨会话记住的教训 → Auto Memory: 写入 "集成测试不要 mock 数据库,原因: ..." → 未来所有会话都能看到这条记忆 4. 用户觉得这应该是团队规则 → CLAUDE.md: 用户手动添加 "测试必须使用真实数据库" → 所有团队成员通过 git 同步这条规则 三层协作: Transcript = 完整的事实记录(审计用) Memory = Claude 提炼的经验(个人学习) CLAUDE.md = 人类制定的规则(团队规范)
4. CLAUDE.md 的加载与持久性 4.1 加载层级与顺序 CLAUDE.md 按以下优先级从多个位置加载(越具体越优先):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1. 托管策略级 (Managed Policy) — 不可排除 ├── Linux/WSL: /etc/claude-code/CLAUDE.md ├── macOS: /Library/Application Support/ClaudeCode/CLAUDE.md └── Windows: C:\Program Files\ClaudeCode\CLAUDE.md 2. 用户级 — 适用于所有项目 └── ~/.claude/CLAUDE.md 3. 项目级 — 从工作目录向上遍历目录树 ├── ./CLAUDE.md 或 ./.claude/CLAUDE.md └── 所有祖先目录的 CLAUDE.md 4. 子目录级 — 按需加载 └── 当 Claude 访问某子目录的文件时,才加载该子目录的 CLAUDE.md
实际加载路径示例 ——假设你在 /home/user/projects/myapp/src 启动 Claude Code:
1 2 3 4 5 6 7 8 9 10 加载顺序(启动时): 1. /etc/claude-code/CLAUDE.md ← 托管策略(如果存在) 2. ~/.claude/CLAUDE.md ← 用户级 3. /home/user/projects/CLAUDE.md ← 祖先目录(如果存在) 4. /home/user/projects/myapp/CLAUDE.md ← 项目根目录 5. /home/user/projects/myapp/.claude/CLAUDE.md ← 项目 .claude 目录 按需加载(Claude 访问文件时): 6. /home/user/projects/myapp/src/CLAUDE.md ← 当 Claude 读取 src/ 下文件时 7. /home/user/projects/myapp/src/api/CLAUDE.md ← 当 Claude 读取 src/api/ 下文件时
4.2 加载细节
时机 :会话启动时加载所有符合条件的 CLAUDE.md(子目录级除外)完整加载 :CLAUDE.md 的全部内容都会加载到上下文中注入方式 :作为用户消息 注入,不是系统提示的一部分HTML 注释 :块级 HTML 注释 (<!-- ... -->) 会被自动剥离以节省 token排除机制 :大型 monorepo 可通过 claudeMdExcludes 设置排除特定 CLAUDE.md
4.3 导入机制 (@path/to/file) CLAUDE.md 支持通过 @path 语法内联导入其他文件,这是管理大型指令集的关键机制。
语法规则 :
1 2 3 4 5 6 7 8 9 # 相对路径 — 相对于当前 CLAUDE.md 所在目录解析(不是工作目录!) @README.md @docs/coding-standards.md # Home 目录 — 导入个人偏好(不进版本控制) @~/.claude/my-personal-style.md # 导入 package.json 让 Claude 知道可用命令 @package.json
约束 :
最大嵌套深度:5 层 (A 导入 B 导入 C 导入 D 导入 E 导入 F → 超限)
循环导入:自动检测并防止无限循环
首次导入外部文件时,Claude Code 会弹出确认对话框
具体的组织示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 myapp/ ├── CLAUDE.md ← 主入口(精简) ├── README.md ├── package.json ├── docs/ │ ├── git-workflow.md │ ├── api-conventions.md │ └── testing-standards.md └── .claude/ └── rules/ ├── code-style.md └── api-rules.md ~/.claude/ └── my-personal-style.md ← 个人偏好,不进版本控制
CLAUDE.md 内容(主入口,保持精简) :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # MyApp @README.md ## 可用命令 @package.json ## 开发规范 @docs/git-workflow.md @docs/api-conventions.md @docs/testing-standards.md ## 个人偏好 @~/.claude/my-personal-style.md ## Compact Instructions When compacting, focus on API changes and test results.
这样 CLAUDE.md 本身只有十几行,但通过导入可以包含丰富的上下文。导入的内容在会话启动时全部展开。
4.4 为什么 CLAUDE.md 如此重要 CLAUDE.md 是唯一在压缩后能完全存活 的用户指令载体。对话中口头给出的指令可能在压缩后丢失,但 CLAUDE.md 中的内容会被重新注入。
1 2 3 4 5 6 7 8 9 10 口头指令: "记住用 pnpm 不要用 npm" → 存在对话历史中 → 第 1 次压缩:可能保留在摘要中 → 第 2 次压缩:可能丢失 → 第 3 次压缩:几乎肯定丢失 CLAUDE.md 中的指令: "Package manager: always use pnpm, never npm" → 每次压缩后从磁盘重新读取 → 永远不会丢失 → 第 100 次压缩后仍然完整存在
原则 :如果一条指令你需要 Claude 在整个会话(以及未来会话)中始终遵守,就把它写进 CLAUDE.md。
推荐大小 :
目标:~200 行以内(每行都消耗 token)
上限:~500 行(超过后 Claude 对指令的遵循度开始下降)
大于 500 行:考虑拆分到 .claude/rules/ 和导入文件
4.5 Rules 系统 (.claude/rules/) Rules 是 CLAUDE.md 的补充——允许将指令按主题拆分,并可以按路径限定作用范围 。
与 CLAUDE.md 的区别 :
维度
CLAUDE.md
.claude/rules/
加载时机
会话启动(全部)
启动(通用规则)+ 按需(路径限定规则)
作用范围
整个项目
可限定到特定文件/目录
适合放
全局约定、项目概述
语言特定、模块特定的规则
上下文开销
每次请求(全部)
通用规则每次请求;路径限定规则仅在访问匹配文件后
通用规则 (无 paths 字段,会话启动即加载):
1 2 3 4 5 6 7 8 <!-- .claude/rules/code-style.md --> # Code Style - 2 空格缩进,不用 tab- 变量名 camelCase,类名 PascalCase- 每行不超过 100 字符- 优先用 const,需要重新赋值才用 let
路径限定规则 (带 YAML frontmatter,按需加载):
1 2 3 4 5 6 7 8 9 10 11 12 <!-- .claude/rules/api-rules.md --> --- paths: - "src/api/**/*.ts" - "src/api/* */* .tsx"--- # API 开发规则 - 所有端点必须包含输入校验 - 使用标准错误响应格式: { error, message, details } - 每个端点上方添加 OpenAPI 注释
1 2 3 4 5 6 7 8 9 10 11 12 <!-- .claude/rules/test-rules.md --> --- paths: - "**/*.test.ts" - "* */* .spec.ts"--- # 测试规则 - 集成测试必须使用真实数据库,不要 mock - 每个测试用例独立,不依赖执行顺序 - 使用 describe/it 结构组织测试
路径匹配模式参考 :
模式
匹配
**/*.ts任意深度的所有 TypeScript 文件
src/api/**/*src/api/ 下所有文件
*.md仅根目录的 markdown 文件
src/**/*.{ts,tsx}src/ 下所有 TS 和 TSX 文件
用户级规则 (适用于所有项目):
1 2 3 4 ~/.claude/rules/ ├── preferences.md # 个人编码偏好 ├── workflows.md # 工作流偏好 └── python.md # Python 相关偏好
路径限定规则只在 Claude 首次访问匹配文件时加载一次。这意味着如果你从不碰 src/api/ 目录,对应的 API 规则永远不会加载——节省了上下文空间。
5. 文件读取与工具结果管理 5.1 文件读取的上下文成本 使用 Read 工具读取文件时,文件内容被添加到对话历史中 ,并一直占用上下文直到被压缩清除。
Read 工具的参数与上下文控制 :
参数
说明
上下文影响
file_path文件路径(必填)
-
limit只读 N 行
大幅减少上下文消耗
offset从第 N 行开始读
跳过不需要的部分
pagesPDF 页码范围
只加载需要的页面
对比示例 ——同一个 1000 行的文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 方式 1: Read file.js(完整读取) → ~4,000 tokens 进入上下文 → 直到压缩才释放 方式 2: Read file.js, limit: 50(只读前 50 行) → ~200 tokens → 节省 95% 方式 3: Read file.js, offset: 200, limit: 50(读第 200-250 行) → ~200 tokens → 精确定位到需要的部分 方式 4: 先用 Grep 搜索关键字,再用 offset+limit 读取周围代码 → Grep 结果 ~100 tokens + 目标代码 ~200 tokens → 最精准,最省上下文
PDF 和图片的特殊情况 :
1 2 3 4 5 6 7 8 PDF 文件: Read report.pdf → 加载全部页面(100 页 ≈ 400K tokens!) Read report.pdf, pages: "1-3" → 仅 3 页 ≈ 12K tokens Read report.pdf, pages: "15-20" → 仅 6 页 ≈ 24K tokens 图片文件: Read screenshot.png → base64 编码,~5K-10K tokens(取决于分辨率) 图片没有 offset/limit 参数,总是完整加载
5.2 重复读取同一文件 如果在对话中多次读取同一文件,每次读取都会在对话历史中添加一条新的工具结果 。Claude Code 不会自动去重。
1 2 3 4 5 Turn 3: Read src/app.js → 文件内容 A 进入上下文 Turn 8: Read src/app.js → 文件内容 A' 再次进入上下文(即使文件没变) Turn 12: Read src/app.js → 文件内容 A'' 第三次进入上下文 上下文中现在有 3 份 app.js 的内容!
最佳实践 :第一次读取后,如果文件没有被修改,不要重复读取。如果需要参考之前读取的内容,可以引用之前的对话轮次。
5.3 工具结果的生命周期 每次工具调用(Read、Bash、Grep 等)的结果都作为独立消息 加入对话历史:
1 2 3 4 5 6 7 8 9 10 11 12 对话历史(简化): [user] "帮我看看 auth 模块" [claude] 调用 Grep("login", path="src/auth/") [tool] Grep 结果: 找到 15 个匹配... ← 占上下文 [claude] 调用 Read("src/auth/login.js") [tool] Read 结果: [500 行代码] ← 占上下文 [claude] 调用 Bash("npm test src/auth/") [tool] Bash 结果: [200 行测试输出] ← 占上下文 [claude] "分析结果..." [user] "好的,现在看看 database 模块" [claude] 调用 Read("src/db/connection.js") ← 上面的结果仍在上下文中 ...
压缩时的处理优先级 :
1 2 3 4 最先清除: 旧的 Bash 命令输出(verbose 日志、测试输出等) 然后清除: 旧的 Read 文件内容 然后清除: 旧的 Grep/Glob 搜索结果 最后压缩: 对话历史本身
重要澄清 :这里的”清除”是指从活跃上下文 (发送给 API 的内容)中移除。没有实用的方式自动找回 这些旧的工具输出——
5.4 使用 Hooks 预处理工具输出 PostToolUse Hook 可以在工具输出到达 Claude 之前进行过滤,减少上下文消耗:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "hooks" : { "PostToolUse" : [ { "matcher" : "Bash" , "hooks" : [ { "type" : "command" , "command" : "if echo \"$TOOL_INPUT\" | grep -q 'npm test'; then echo \"$TOOL_OUTPUT\" | grep -E '(FAIL|PASS|Error)'; fi" } ] } ] } }
上面的例子在运行 npm test 后,只保留包含 FAIL/PASS/Error 的行,过滤掉几百行的详细测试日志。
5.5 上下文成本总结 1 2 3 4 5 6 7 8 9 10 11 操作 估计 token 成本 建议 ───────────────────────────────────────────────────────── 读取 100 行代码文件 ~400 tokens ✅ 正常 读取 1000 行代码文件 ~4,000 tokens ⚠️ 考虑用 offset+limit 读取 5000 行代码文件 ~20,000 tokens ❌ 一定要分段读取 运行 npm test(简短输出) ~200 tokens ✅ 正常 运行 npm test(verbose 输出) ~5,000+ tokens ⚠️ 用 Hook 过滤 Grep 搜索结果(20 个匹配) ~300 tokens ✅ 正常 读取 100 页 PDF ~400,000 tokens ❌ 一定要用 pages 参数 读取截图 ~5,000-10,000 ⚠️ 注意大图 子代理内的所有操作 0 tokens (隔离) ✅ 推荐用于大量搜索
6. 子代理 (Subagent) 的上下文隔离 子代理是 Claude Code 中最重要的上下文管理设计之一 ——它允许将高上下文消耗的工作”外包”到独立的上下文窗口中,只将摘要结果带回主会话。
6.1 完全隔离模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ┌────────────────────────┐ ┌────────────────────────┐ │ 主会话上下文 │ │ 子代理上下文 │ │ │ │ │ │ ┌──────────────────────┐ │ │ ┌──────────────────────┐ │ │ │ System Prompt │ │ ←共享→ │ │ System Prompt │ │ │ │ CLAUDE.md │ │ ←共享→ │ │ CLAUDE.md │ │ │ │ 对话历史 (20轮) │ │ │ │ 仅有 spawn prompt │ │ │ │ 已读文件 (15个) │ │ │ │ (全新的独立上下文) │ │ │ │ 工具结果 (30个) │ │ │ │ │ │ │ │ ~150K tokens 已用 │ │ │ │ ~5K tokens 开始 │ │ │ └──────────────────────┘ │ │ └──────────────────────┘ │ │ │ │ │ │ ← ─ ─ ─ 摘要返回 ─ ─ ─ ─ ─ ─ ─ │ 子代理内部: │ │ (~500 tokens) │ │ 读取 30 个文件 │ │ │ │ 运行 50 次搜索 │ │ │ │ 消耗 ~100K tokens │ │ │ │ 但这些都不影响主会话! │ └────────────────────────┘ └────────────────────────┘
6.2 Spawn 和返回的完整流程 传递给子代理的内容 :
内容
传递方式
System Prompt
共享(Prompt Caching 优化)
CLAUDE.md + Rules
继承
Git 状态
继承
Spawn Prompt(任务描述)
由父代理编写的任务描述
Skills(预加载的)
如果在 skills: 字段中指定
不传递给子代理的内容 :
内容
说明
对话历史
子代理从零开始
已读文件内容
子代理需要自己读
之前的工具结果
完全隔离
已调用的 Skills
除非在 frontmatter 中预加载
权限设置
继承父代理权限,但可覆盖
返回给主会话的内容 :
1 2 3 4 5 6 7 8 9 子代理完成后返回: ├── 摘要结果(Claude 综合的发现/结论) ├── Agent ID(用于后续通过 SendMessage 恢复对话) └── 使用统计(token 数、工具调用数、耗时) 不返回: ├── 完整的对话 transcript(留在子代理自己的存储中) ├── 所有中间步骤和探索过程 └── 读取的文件原始内容
具体例子 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 用户: "帮我调研一下这个项目的 auth 模块用了什么设计模式" 主会话 Claude: → 生成子代理,传入 prompt: "Research the auth module in src/auth/. Read all relevant files, analyze the design patterns used, and return a summary of: 1. Main patterns identified 2. Key files and their roles 3. Potential improvement areas" Explore 子代理(独立上下文): → 读取 src/auth/index.js (200行) 消耗子代理上下文 → 读取 src/auth/middleware.js (300行) 消耗子代理上下文 → 读取 src/auth/strategies/ (5个文件) 消耗子代理上下文 → Grep "pattern|factory|singleton" ... 消耗子代理上下文 → 读取 src/auth/tests/ (3个文件) 消耗子代理上下文 → 分析所有内容... 总计: 读取 ~3000 行代码,消耗 ~50K tokens ↓ 返回摘要 (~500 tokens): "Auth module uses Strategy pattern for authentication providers, Factory pattern for session creation, and Middleware chain pattern for request processing. Key files: ..." 主会话上下文增加: ~500 tokens(而不是 50K tokens!)
6.3 前台 vs 后台子代理
维度
前台 (Foreground)
后台 (Background)
阻塞
父代理等待完成
父代理继续工作
用户交互
可以向用户提问
不能提问(权限预先获取)
结果返回
完成后立即返回
完成后以系统消息通知
适用场景
需要立即使用结果
长时间运行、可并行的任务
后台子代理的实际使用场景 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 用户: "在后台运行测试,同时帮我重构 auth 模块" Claude: 1. 生成后台子代理: "Run full test suite, report only failures" → 子代理开始运行(不阻塞) 2. 同时在主会话中开始重构 auth 模块 → 读取文件、编辑代码... 3. [2 分钟后] 后台子代理完成 → 系统消息: "Test agent completed: 3 failures found in..." → 结果加入主会话上下文 主会话上下文: 重构工作 + 测试摘要 不包含: 子代理运行测试的完整输出
6.4 Worktree 隔离模式 isolation: "worktree" 不仅隔离上下文,还隔离文件系统 :
1 2 3 4 5 6 7 8 正常子代理: 主会话 → /myapp/src/auth/login.js ← 子代理 (共享同一个文件系统,子代理的修改主会话立刻可见) Worktree 隔离子代理: 主会话 → /myapp/src/auth/login.js 子代理 → /myapp/.git/worktrees/claude-temp-xxxxx/src/auth/login.js (完全独立的文件副本,互不影响)
适用于:子代理需要做实验性修改、checkout 不同分支、或有冲突风险的场景。
6.5 通过 SendMessage 恢复子代理 子代理完成后,可以通过 SendMessage 恢复之前的对话,子代理保留完整的上下文历史 :
1 2 3 4 5 6 7 8 第一次交互: 子代理 agent-12345: 调研了 auth 模块,返回摘要 第二次交互(通过 SendMessage 恢复): SendMessage(to: "agent-12345", message: "继续分析 database 层") → agent-12345 恢复,带着之前的完整上下文 → 不需要重新读取 auth 模块的文件(之前已经读过了) → 在已有的知识基础上继续工作
这比生成新子代理更高效——新子代理需要从零开始,可能重复读取相同的文件。
6.6 子代理类型与工具权限
代理类型
模型
可用工具
典型用途
Explore Haiku(快速)
Read, Grep, Glob, Bash(只读)
快速代码搜索和探索
Plan 继承父代理
Read, Grep, Glob, Bash(只读)
制定实施方案
General-purpose 继承父代理
所有工具
复杂多步骤任务
选择指南 :
1 2 3 4 5 6 7 8 9 10 11 "在代码库中找到所有用了 deprecated API 的地方" → Explore 子代理(快速搜索,Haiku 模型省成本) "分析这个 bug 的根因并制定修复方案" → Plan 子代理(需要深度分析,但不修改代码) "在独立分支上实现这个新功能并写测试" → General-purpose 子代理 + worktree 隔离 "帮我读一下这个文件" → 不需要子代理,直接用 Read 工具(子代理有启动开销)
6.7 好的 vs 坏的子代理使用模式 好的模式 ——利用子代理隔离上下文:
1 2 3 4 5 6 7 8 9 10 11 12 13 ✅ 用子代理做大量搜索: "Use Explore agent to find all API endpoints and their middleware chains" → 子代理读取 40 个文件,只返回摘要 ✅ 用后台子代理做测试: "Run tests in background while I continue coding" → 测试输出不进主上下文 ✅ 并行子代理做独立调研: 子代理 A: "Research authentication patterns" 子代理 B: "Research database access patterns" 子代理 C: "Research API design patterns" → 三个独立调研并行进行,各自隔离
坏的模式 ——不必要地使用(或不使用)子代理:
1 2 3 4 5 6 7 8 9 10 ❌ 用子代理读一个文件: "Use agent to read src/config.js" → 子代理启动开销 > 直接 Read 的成本 ❌ 需要频繁交互的任务用子代理: 子代理不能和用户直接交互(除了前台模式有限的交互) ❌ 明明应该用子代理却直接在主会话操作: "Read all 50 test files and summarize" → 50 个文件的内容全进了主会话上下文!应该用 Explore 子代理
7. 持久化记忆系统 (Auto Memory) Auto Memory 是 Claude Code 的跨会话持久化机制 ——让 Claude 在不同会话之间”记住”关于用户、项目和工作偏好的信息。它与上下文管理密切相关,因为记忆内容占用上下文空间,同时也是对抗压缩造成信息丢失的重要工具。
7.1 存储结构 目录位置 :
1 ~/.claude/projects/<项目标识>/memory/
其中 <项目标识> 由 git 仓库根目录路径派生。同一 git 仓库下的所有 worktree 和子目录共享同一个 memory 目录。非 git 仓库使用项目根目录路径。
可通过设置自定义位置:
1 2 3 4 { "autoMemoryDirectory" : "~/my-custom-memory-dir" }
目录结构 :
1 2 3 4 5 6 ~/.claude/projects/home-user-projects-myapp/memory/ ├── MEMORY.md # 索引文件(前 200 行自动加载) ├── user_role.md # 记忆文件:用户角色和背景 ├── feedback_testing.md # 记忆文件:测试相关的反馈 ├── project_auth.md # 记忆文件:认证模块的项目信息 └── reference_linear.md # 记忆文件:外部系统引用
7.2 记忆文件格式 MEMORY.md(索引文件) :
MEMORY.md 是纯 Markdown,没有 frontmatter,作为所有记忆的索引入口。每条记忆是一行简短描述 + 链接:
1 2 3 4 5 - [User Role ](user_role.md ) — senior backend engineer, new to React- [Testing Preferences ](feedback_testing.md ) — integration tests must use real DB, not mocks- [Auth Module Context ](project_auth.md ) — JWT migration driven by compliance requirements- [Linear Project ](reference_linear.md ) — pipeline bugs tracked in Linear project "INGEST"- [API Conventions ](feedback_api.md ) — prefer single bundled PR for refactors in api/ directory
关键约束:前 200 行限制 。MEMORY.md 超过 200 行的内容不会在会话启动时自动加载。因此:
保持 MEMORY.md 精简,每条记忆一行
详细内容放在具体的记忆文件中
如果索引过长,考虑合并或清理旧条目
具体记忆文件格式 :
每个记忆文件使用 YAML frontmatter + 正文内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 --- name: Testing Preferences description: Integration tests must use real database — prior incident with mock/prod divergence type: feedback --- Integration tests must hit a real database, not mocks. **Why:** Last quarter a mock-based test suite passed but the prod migration failed becausethe mock didn't accurately represent the actual PostgreSQL constraint behavior. **How to apply:** When writing or reviewing tests for database-interacting code, alwaysconfigure a test database connection. Use transaction rollback for cleanup, not mock objects.
7.3 记忆的四种类型
类型
用途
何时保存
示例
user 用户角色、偏好、知识水平
了解到用户身份或偏好时
“用户是资深后端工程师,第一次接触 React”
feedback 用户纠正或确认的行为模式
用户说”不要这样做”或”这样很好”
“重构时偏好单个大 PR 而非多个小 PR”
project 项目动态、目标、截止日期
了解到项目规划或约束时
“3月5日开始代码冻结,为移动端发版做准备”
reference 外部系统的指针和位置
了解到外部资源时
“Pipeline bugs 在 Linear 的 INGEST 项目中跟踪”
type 影响 Claude 如何组织和使用记忆 。例如 feedback 类型的记忆会影响 Claude 的行为模式,而 reference 类型只在需要查找外部信息时被参考。
7.4 记忆的写入过程 Claude 写入记忆是一个两步过程 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 步骤 1: 写入具体记忆文件 ──────────────────────── Claude 使用 Write 工具创建(或 Edit 工具更新)一个记忆文件: 文件: ~/.claude/projects/.../memory/feedback_testing.md 内容: --- name: Testing Preferences description: Integration tests must use real database type: feedback --- Integration tests must hit a real database, not mocks. **Why:** Prior incident where mock/prod divergence masked a broken migration. **How to apply:** Always configure test database connection for DB tests. 步骤 2: 更新 MEMORY.md 索引 ──────────────────────── Claude 使用 Edit 工具在 MEMORY.md 中添加一行: - [Testing Preferences](feedback_testing.md) — integration tests must use real DB
什么时候 Claude 会写入记忆 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ✅ 会写入的场景: 用户: "我是数据科学家,正在调查日志系统" → 保存 user 记忆:用户角色和当前关注点 用户: "不要 mock 数据库,我们上次被坑过" → 保存 feedback 记忆:测试必须用真实数据库 用户: "周四之后冻结所有非关键的 merge" → 保存 project 记忆:2026-03-05 开始代码冻结 用户: "bug 都在 Linear 的 INGEST 项目里跟踪" → 保存 reference 记忆:外部系统位置 ❌ 不会写入的场景: 可以从代码/git 历史推导出的信息(架构、文件结构、代码风格) 临时的对话上下文("我现在在调试这个函数") 已经在 CLAUDE.md 中记录的内容 调试方案或修复方法(修复在代码中,上下文在 commit message 中) 敏感信息(密钥、凭证)
7.5 记忆的加载与上下文的交互 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 会话启动时: ══════════════════════════════════════════════════ 上下文窗口 MEMORY.md (前 200 行) ──自动注入──→ ┌──────────┐ │ System │ 具体记忆文件 ──── 不加载 ────→ ✗ │ Prompt │ │ │ │ CLAUDE.md│ │ │ │ MEMORY.md│ ← 前 200 行 │ (索引) │ │ │ │ Skills │ │ 描述 │ └──────────┘ 会话中 (Claude 需要某条记忆的详细信息): ══════════════════════════════════════════════════ Claude: "让我检查之前关于测试的偏好..." → Read feedback_testing.md → 文件内容进入对话历史 ┌──────────┐ │ ... │ │ MEMORY.md│ │ │ │ 对话历史 │ │ ... │ │ [Read │ │ result: │ │ testing │ ← 按需读取的记忆内容 │ prefs] │ │ ... │ └──────────┘ 压缩后: ══════════════════════════════════════════════════ MEMORY.md ──从磁盘重新加载──→ ✅ 完整保留 之前读取的记忆文件内容 → ⚠️ 可能在摘要中被压缩 (作为对话历史的一部分) (如果需要,Claude 需要重新 Read)
7.6 记忆 vs CLAUDE.md——何时用哪个
维度
CLAUDE.md
Auto Memory
写入者 人类(你)
Claude(自动)
内容 规则、指令、约定
发现、偏好、学习
加载方式 全部加载(每次请求)
索引 200 行(每次请求),详情按需读取
压缩存活 完全存活 (从磁盘重新读取)索引存活 ,详情需要重新读取
版本控制 通常入 git
通常不入 git(~/.claude/ 下)
跨机器 通过 git 同步
不同步 (机器本地)
适合放 “用 pnpm 不要用 npm”
“用户是后端资深工程师,新学 React”
决策流程图 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 这条信息在未来的会话中是否需要? │ ├── 否 → 不保存(临时对话上下文,用任务追踪即可) │ └── 是 │ 这条信息是你(人类)制定的规则还是 Claude 发现的? │ ├── 人类制定的规则/约定 → 写入 CLAUDE.md │ 例: "所有 API 端点必须有 OpenAPI 注释" │ └── Claude 从交互中学到的 │ 可以从代码/git 推导出来吗? │ ├── 可以 → 不保存(读代码即可) │ └── 不可以 → 写入 Auto Memory 例: "用户偏好重构时用单个大 PR"
7.7 记忆的陈旧与验证 记忆没有内置的过期机制 。一条记忆写入后可能过时:
1 2 3 4 5 6 危险场景: 记忆: "build 命令是 npm run build" 实际: 项目已经迁移到 pnpm,现在是 "pnpm build" 记忆: "auth 模块的入口是 src/auth/index.js" 实际: 文件已经被重命名为 src/auth/main.ts
Claude 的验证策略 (内建于系统提示中):
如果记忆提到一个文件路径 → 先检查文件是否存在
如果记忆提到一个函数或命令 → 先 grep 确认
如果用户要基于记忆采取行动(而不只是询问历史)→ 先验证
如果记忆和当前观察到的事实矛盾 → 信任当前事实,更新记忆
用户维护记忆的方法 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /memory vim ~/.claude/projects/.../memory/MEMORY.md vim ~/.claude/projects/.../memory/feedback_testing.md rm ~/.claude/projects/.../memory/old_project_info.md用户: "忘掉关于测试偏好的记忆" Claude: [删除 feedback_testing.md,更新 MEMORY.md] 用户: "记住我们的 API 版本策略是..." Claude: [创建新记忆文件,更新 MEMORY.md]
7.8 子代理的记忆系统 自定义子代理可以有自己独立的持久化记忆:
1 2 3 4 5 --- name: code-reviewer description: Reviews code for quality memory: project ---
三种记忆作用域 :
作用域
存储位置
使用场景
user~/.claude/agent-memory/<agent-name>/跨项目通用的记忆
project.claude/agent-memory/<agent-name>/项目特定,可入 git
local.claude/agent-memory-local/<agent-name>/项目特定,不入 git
子代理的记忆同样遵循 200 行的 MEMORY.md 限制,并且自动启用 Read、Write、Edit 工具用于记忆管理。
7.9 记忆系统的上下文成本分析 1 2 3 4 5 6 7 8 9 10 11 12 13 固定成本(每次请求): MEMORY.md 前 200 行 ≈ 几百到几千 tokens(取决于内容密度) 可变成本(按需): 每次 Read 一个记忆文件 ≈ 200-2000 tokens 进入对话历史后随对话累积 压缩时作为对话历史的一部分被摘要 优化策略: ├── MEMORY.md 保持精简(每条一行,< 150 字符) ├── 详细内容放在具体文件中(不自动加载) ├── 定期清理过时记忆 └── 不要在 MEMORY.md 中放大段文字(放到具体文件中链接过去)
7.10 记忆系统配置 1 2 3 4 5 6 7 8 9 10 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 claude { "autoMemoryEnabled" : false } /memory
注意 :Auto Memory 需要 Claude Code v2.1.59 或更高版本。
8. Token 计数与预算管理 8.1 监控工具
命令
功能
/cost显示当前会话的详细 token 使用统计
/stats显示使用模式(订阅用户)
/context显示什么在消耗上下文空间
/mcp显示每个 MCP server 的上下文成本
状态栏
可配置为持续显示上下文窗口使用率
8.2 MCP Server 的上下文成本 每个 MCP Server 都会将其工具定义添加到每一次请求 中:
1 2 3 4 5 MCP Server A (5 个工具) → ~X tokens × 每次请求 MCP Server B (10 个工具) → ~Y tokens × 每次请求 MCP Server C (20 个工具) → ~Z tokens × 每次请求 ─────────────────────────────────────────── 总计:还没开始工作就已消耗大量上下文
MCP Tool Search 优化 :
默认启用,当工具定义超过上下文的 10% 时触发
将不常用的工具定义延迟加载 (deferred),只在需要时获取
可通过 ENABLE_TOOL_SEARCH=auto:<N> 自定义阈值(如 auto:5 表示 5% 时触发)
8.3 各功能的上下文成本总结
功能
加载时机
上下文成本
CLAUDE.md
会话启动
每次请求(全部内容)
Skills 描述
会话启动
每次请求(仅描述)
Skills 完整内容
调用时
仅在使用时
MCP 工具定义
会话启动
每次请求
Auto Memory
会话启动
每次请求(前 200 行)
子代理
生成时
隔离上下文(不影响主会话)
文件读取
按需
累积到被压缩
9. 会话管理与检查点 9.1 会话生命周期 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 新会话启动 │ ├── 加载 System Prompt ├── 加载 CLAUDE.md (所有层级) ├── 加载 MEMORY.md (前 200 行) ├── 加载 Skills 描述 ├── 加载 MCP 工具定义 │ ▼ 对话循环 │ ├── 用户消息 + Claude 回复 = 一个轮次 ├── 上下文持续累积 ├── 接近 95% → 触发自动压缩 │ ├── 清除旧工具输出 │ ├── 摘要化旧对话 │ └── 重新注入 CLAUDE.md + Memory ├── 继续对话循环... │ ▼ 会话结束 └── 会话历史持久化到磁盘
9.2 会话恢复
claude --continue:恢复最近的会话,加载完整对话历史claude --resume:选择并恢复特定会话--fork-session:从某个会话分叉出新会话(保留到分叉点的历史)每个新会话(非恢复)从全新上下文 开始
9.3 检查点系统
每次文件编辑前 ,Claude 会快照文件状态/rewind 或双击 Escape 可以回退到任意之前的状态检查点在同一 session ID 内跨会话持久化
只追踪文件变更(不追踪外部系统变更)
不能替代 git
10. 其他优化机制 10.1 Prompt Caching
默认自动启用 缓存重复内容(如系统提示),减少 API 成本
可通过环境变量禁用:
DISABLE_PROMPT_CACHING=1(全局)DISABLE_PROMPT_CACHING_HAIKU=1(仅 Haiku)
10.2 Effort Level(自适应思考) 根据任务复杂度动态分配 thinking tokens:
级别
说明
low
最少 thinking tokens,适合简单任务
medium
默认级别
high
更多 thinking tokens,适合复杂任务
max
最大 thinking tokens(仅 Opus 4.6)
Thinking tokens 消耗输出侧 token 预算,可通过 MAX_THINKING_TOKENS 环境变量限制。
10.3 扩展上下文窗口 (1M Token)
使用 opus[1m] 或 sonnet[1m] 模型别名启用
提供 100 万 token 上下文,适合长会话和大型代码库
在 Max、Team、Enterprise 计划中可用
10.4 Hooks 对上下文的影响 Hooks 在特定生命周期事件时运行外部脚本:
不消耗上下文 ——除非 hook 返回输出可以在数据到达 Claude 之前预处理(如过滤测试输出只保留失败项)
相关事件:PreCompact、PostCompact、PreToolUse、PostToolUse 等
11. 最佳实践 节省上下文
在无关任务之间使用 /clear — 释放全部对话上下文使用 /compact <焦点> 手动压缩 — 在需要时主动压缩,并指导保留重点CLAUDE.md 控制在 ~500 行以内 — 过长会降低遵循度将详细参考材料放入 Skills — 按需加载,不占常驻上下文使用子代理进行探索和大量搜索 — 隔离上下文开销禁用不使用的 MCP Server — 减少固定工具定义开销使用 Hooks 预处理冗长输出 — 在到达 Claude 之前过滤读取文件时指定行范围 — 避免读取整个大文件使用 Grep/Glob 代替全文读取 — 更精准,更节省
利用上下文
持久指令放 CLAUDE.md — 压缩后依然存活跨会话知识放 Memory — 在未来会话中可用复杂任务用子代理 — 独立上下文,不互相干扰监控上下文使用 — 配置状态栏显示使用率,使用 /cost 查看详情
12. 深入实现:Memory 机制的内部工作原理 前面第 7 章介绍了 Memory 系统的使用方式。这一章深入其内部实现 ——它是如何被注入、触发、读写的,以及你如何用 Python 复刻一个类似的机制。
12.1 揭开魔法:Memory 只是”文本注入 + 文件读写” Claude Code 的 Memory 系统没有使用任何特殊的 API 或工具 。它的实现本质上只有两部分:
1 2 1. 文本注入:在会话开始时,将 MEMORY.md 前 200 行作为上下文文本注入对话 2. 文件读写:Claude 使用标准的 Read / Write / Edit 工具操作 memory 目录下的文件
没有专门的 “memory tool”,没有嵌入式向量搜索,没有数据库。全部是纯文本文件 + 系统提示中的指令 。
12.2 实现细节拆解 步骤 1:会话启动时的注入流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Claude Code 启动一个会话时,内部执行以下步骤: 1. 构建 System Prompt(模型的系统指令) 2. 构建 Messages 数组的第一条消息(注入上下文): ├── 读取托管策略 CLAUDE.md(如果存在) ├── 读取项目级 CLAUDE.md(+ @import 展开) ├── 读取 .claude/rules/ 下的规则文件 ├── 读取用户级 ~/.claude/CLAUDE.md ├── 读取 MEMORY.md,截断到前 200 行 ← Memory 注入点 └── 组合为一条 user message 注入对话 3. 在 System Prompt 中包含 Memory 管理指令: "You have a persistent, file-based memory system at <path>. This directory already exists — write to it directly... [详细的何时读、何时写、如何组织的指令]" 4. 等待用户第一条消息
关键点 :Memory 的”智能”完全来自 System Prompt 中的指令。Claude Code 在系统提示中嵌入了一大段关于如何管理记忆的指令(何时保存、保存什么格式、何时读取、如何验证),模型根据这些指令决定自己的行为。
步骤 2:内存目录路径的计算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import osdef get_memory_dir (working_dir: str ) -> str : git_root = find_git_root(working_dir) if git_root: project_id = git_root.strip("/" ).replace("/" , "-" ) else : project_id = working_dir.strip("/" ).replace("/" , "-" ) return os.path.expanduser(f"~/.claude/projects/{project_id} /memory/" )
步骤 3:MEMORY.md 的 200 行截断 1 2 3 4 5 6 7 8 9 10 11 12 13 def load_memory_index (memory_dir: str ) -> str : memory_md = os.path.join(memory_dir, "MEMORY.md" ) if not os.path.exists(memory_md): return "" with open (memory_md, "r" ) as f: lines = f.readlines() truncated = lines[:200 ] return "" .join(truncated)
步骤 4:Memory 写入触发——模型驱动,不是规则驱动 没有显式的触发器。 Claude 在每次回复时都可以决定是否写入记忆。这个决策完全由模型自己根据系统提示中的指令做出 ,不是由 Claude Code 的代码逻辑控制的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 系统提示中的核心指令(简化版): "When to save: - user type: 当你了解到用户的角色、偏好、知识水平 - feedback type: 当用户纠正你的做法 或 确认了一个非显然的方式 - project type: 当你了解到谁在做什么、为什么、截止日期 - reference type: 当你了解到外部系统中资源的位置 What NOT to save: - 可以从代码或 git 历史推导的信息 - 调试方案(修复在代码中,上下文在 commit message 中) - CLAUDE.md 中已有的内容 - 临时的会话上下文 How to save: Step 1: 用 Write 工具创建记忆文件(带 frontmatter) Step 2: 用 Edit 工具更新 MEMORY.md 索引"
模型读到这些指令后,在对话过程中自行判断——“这条信息对未来会话有用吗?”如果有用,就调用 Write/Edit 工具操作文件系统。
步骤 5:Memory 读取——无语义搜索,纯路径查找 1 2 3 4 5 6 7 8 9 用户: "我们之前关于测试的约定是什么?" Claude 的决策过程: 1. 查看已加载的 MEMORY.md 索引(已在上下文中) 2. 找到: "- [Testing Preferences](feedback_testing.md) — real DB, not mocks" 3. 判断需要详细信息 4. 调用 Read 工具: Read("~/.claude/.../memory/feedback_testing.md") 5. 文件内容进入对话历史 6. 根据内容回答用户
没有嵌入式搜索、没有向量数据库、没有全文索引。就是:看索引 → 找路径 → 读文件 。
12.3 完整的数据流图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 ┌─────────────────────────────────────────────────────────────────┐ │ 会话启动 │ │ │ │ 磁盘文件 注入到活跃上下文 │ │ ───────── ────────────── │ │ │ │ MEMORY.md ──[读取前200行]──→ messages[0] 的一部分 │ │ (索引文件) (和 CLAUDE.md 一起作为 │ │ user message 注入) │ │ │ │ feedback_testing.md ──── 不加载 (等 Claude 主动 Read) │ │ project_auth.md ──── 不加载 │ │ │ ├─────────────────────────────────────────────────────────────────┤ │ 对话中:Memory 读取 │ │ │ │ Claude 看到 MEMORY.md 索引中的条目 │ │ → 决定需要详细信息 │ │ → 调用 Read("feedback_testing.md") ← 标准 Read 工具 │ │ → 文件内容加入对话历史 │ │ │ ├─────────────────────────────────────────────────────────────────┤ │ 对话中:Memory 写入 │ │ │ │ 用户: "不要 mock 数据库" │ │ Claude 判断: 这对未来有用 → 触发写入 │ │ │ │ Step 1: Write("feedback_testing.md", │ │ "---\nname: ...\ntype: feedback\n---\n内容...") │ │ ← 标准 Write 工具 │ │ │ │ Step 2: Edit("MEMORY.md", │ │ old="最后一行", new="最后一行\n- [Testing](...)...") │ │ ← 标准 Edit 工具 │ │ │ ├─────────────────────────────────────────────────────────────────┤ │ 压缩后 │ │ │ │ MEMORY.md ──[重新读取前200行]──→ 重新注入活跃上下文 │ │ 之前 Read 过的记忆文件内容 ──→ 随对话历史一起被摘要化 │ │ │ └─────────────────────────────────────────────────────────────────┘
12.4 设计哲学:为什么这么”简单”就够了 Claude Code 的 Memory 系统之所以不需要向量数据库或复杂的检索机制,是因为:
索引足够小 (200 行),模型可以”一眼扫完”在上下文中找到相关条目模型本身就是检索引擎 ——Claude 能理解自然语言索引条目的语义,不需要关键词匹配文件数量有限 ——一个项目通常只有十几个记忆文件,不需要数据库按需深读 ——只在需要时 Read 具体文件,不预加载所有内容
这种设计的经验数据:
指标
结果
200 行以内的 MEMORY.md
92% 规则遵循率
400 行以上的 MEMORY.md
71% 规则遵循率
5 个文件 × 30 行 vs 1 个文件 × 150 行
96% vs 较低的遵循率
具体指令 (“用 2 空格缩进”)
95% 遵循率
模糊指令 (“格式化好一点”)
40% 遵循率
12.5 记忆内容的生成:一次完整的 API 交互追踪 这是理解 Memory 机制最关键的部分——记忆内容(文件名、frontmatter、正文)全部由模型生成 ,不是程序代码生成的,也不是人类预先写好的。
下面用一个具体例子追踪完整的 API 交互过程。
场景:用户说了一句 “不要 mock 数据库” 第 1 步:Claude Code 发送 API 请求
Claude Code 把用户消息 + 历史 + 工具定义打包发给 Claude API:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 { "model" : "claude-sonnet-4-20250514" , "system" : "You are a helpful assistant with a persistent memory system...\n[详细的记忆管理指令]" , "tools" : [ { "name" : "Write" , "description" : "Write a file to disk" , "input_schema" : { ...} } , { "name" : "Edit" , "description" : "Edit a file on disk" , "input_schema" : { ...} } , { "name" : "Read" , "description" : "Read a file from disk" , "input_schema" : { ...} } , ] , "messages" : [ { "role" : "user" , "content" : "[System: memory index]\n- [User Profile](user_profile.md) -- ...\n[End]" } , { "role" : "assistant" , "content" : "Memory loaded." } , { "role" : "user" , "content" : "不要 mock 数据库,我们上次被坑过,mock 的测试通过了但真实的 PostgreSQL 迁移挂了" } ] }
第 2 步:模型内部决策(不可见)
模型收到请求后,在 thinking 中进行推理(简化示意):
1 2 3 4 5 6 7 8 9 [模型内部 thinking] 用户说"不要 mock 数据库"并解释了原因。 这是一条 feedback 类型的信息——用户纠正了一个做法。 根据系统提示中的指令,我应该: 1. 判断这是否对未来有用 → 是的,这影响以后写测试的方式 2. 确定记忆类型 → feedback(用户纠正做法) 3. 生成文件内容(需要包含 Why 和 How to apply) 4. 调用 Write 工具写入文件 5. 调用 Edit 工具更新 MEMORY.md 索引
第 3 步:模型返回 tool_use 响应(记忆内容在这里生成)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 { "stop_reason" : "tool_use" , "content" : [ { "type" : "text" , "text" : "好的,我记住了。以后写集成测试时会使用真实数据库。" } , { "type" : "tool_use" , "id" : "toolu_01ABC..." , "name" : "Write" , "input" : { "file_path" : "/home/user/.claude/projects/.../memory/feedback_testing.md" , "content" : "---\nname: Testing Preferences\ndescription: Integration tests must use real database, not mocks\ntype: feedback\n---\n\nIntegration tests must hit a real database, not mocks.\n\n**Why:** Mock-based tests passed but the real PostgreSQL migration\nfailed in production because the mock didn't represent actual\nconstraint behavior.\n\n**How to apply:** When writing tests for database-interacting code,\nalways configure a test database connection. Use transaction rollback\nfor cleanup, not mock objects.\n" } } ] }
注意 :content 字段中的每一个字——文件名 feedback_testing.md、frontmatter 的 name/description/type、正文中的 **Why:** 和 **How to apply:** 结构——全部是模型根据系统提示中的格式要求自己生成的。Claude Code 的代码不参与内容生成。
第 4 步:Claude Code 执行工具调用
Claude Code 收到这个 tool_use 响应后,执行的代码逻辑非常简单:
1 2 3 4 5 6 7 8 if tool_name == "Write" : file_path = tool_input["file_path" ] content = tool_input["content" ] with open (file_path, "w" ) as f: f.write(content) result = f"Written to {file_path} "
第 5 步:Claude Code 把工具结果喂回模型
1 2 3 4 5 6 7 8 9 10 { "messages" : [ { "role" : "assistant" , "content" : [ 上面的 text + tool_use blocks] } , { "role" : "user" , "content" : [ { "type" : "tool_result" , "tool_use_id" : "toolu_01ABC..." , "content" : "Written to feedback_testing.md" } ] } ] }
第 6 步:模型继续——调用第二个工具更新索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { "stop_reason" : "tool_use" , "content" : [ { "type" : "tool_use" , "id" : "toolu_02DEF..." , "name" : "Edit" , "input" : { "file_path" : "/home/user/.claude/projects/.../memory/MEMORY.md" , "old_string" : "(MEMORY.md 的最后一行)" , "new_string" : "(最后一行)\n- [Testing Preferences](feedback_testing.md) -- use real DB, not mocks" } } ] }
第 7 步:Claude Code 执行 Edit,喂回结果,模型返回最终回复
1 2 3 4 5 6 7 8 9 10 { "stop_reason" : "end_turn" , "content" : [ { "type" : "text" , "text" : "我已经记录下了这个偏好。以后在写集成测试时,我会使用真实的数据库连接,而不是 mock。" } ] }
完整的请求-响应时序图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Claude Code Claude API (模型) │ │ │ 请求 1: 用户消息 + tools 定义 │ │ ─────────────────────────────────→ │ │ │ [thinking: 这条值得记住] │ │ [生成 Write tool call] │ 响应 1: text + tool_use(Write) │ │ ←───────────────────────────────── │ │ │ │ [执行文件写入] │ │ feedback_testing.md 已写入磁盘 │ │ │ │ 请求 2: tool_result("Written...") │ │ ─────────────────────────────────→ │ │ │ [继续: 还需要更新索引] │ │ [生成 Edit tool call] │ 响应 2: tool_use(Edit MEMORY.md) │ │ ←───────────────────────────────── │ │ │ │ [执行索引更新] │ │ MEMORY.md 已更新 │ │ │ │ 请求 3: tool_result("Updated...") │ │ ─────────────────────────────────→ │ │ │ [两步都完成了,回复用户] │ 响应 3: end_turn + 最终文本回复 │ │ ←───────────────────────────────── │ │ │ │ [显示回复给用户] │
关键洞察 1 2 3 4 5 6 7 8 9 10 11 12 整个过程中 Claude Code 的代码只做了三件事: 1. 把用户消息 + 工具定义 + 系统提示打包发给 API 2. 收到 tool_use 响应后,执行文件操作(纯 I/O,零智能) 3. 把执行结果喂回 API 所有"智能"决策都发生在模型侧: · 是否值得保存 → 模型判断 · 保存什么类型 → 模型选择 · 文件名叫什么 → 模型生成 · 正文怎么措辞 → 模型生成 · 索引条目怎么写 → 模型生成 · 先写文件再更新索引的顺序 → 模型遵循系统提示中的指令
12.6 Python 实现:复刻一个 Claude Code 风格的 Memory 系统 memory_system_example.py
代码结构对应关系 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Claude Code 内部组件 Python 示例中的对应 ────────────────────── ────────────────── memory 目录管理 MemoryManager 类 ├── 路径计算 __init__() 中的 project_id 计算 ├── 200 行截断 load_index() 中的 lines[:200] ├── 文件读写 read_file() / write_file() └── 索引更新 update_index() Tool 定义(暴露给模型的接口) MEMORY_TOOLS 列表 ├── Read → memory_read 对应 Claude Code 的通用 Read 工具 ├── Write → memory_write 对应 Claude Code 的通用 Write 工具 └── Edit → memory_update_index 对应 Claude Code 的通用 Edit 工具 System Prompt(记忆管理指令) SYSTEM_PROMPT 字符串 ├── 何时保存 "When to Save" 节 ├── 保存什么格式 "How to Save" 节(frontmatter 格式) ├── 何时读取 "When to Read" 节 └── 不保存什么 "Do NOT save" 节 Tool 执行引擎 handle_tool_call() 函数 └── 收到 tool_use → 执行 → 返回结果 纯 I/O 分发,零智能 对话引擎(tool use 循环) call_model_with_tool_loop() 函数 └── 请求 → tool_use? → 执行 → 喂回 while True 循环直到 end_turn → 重复直到 end_turn 会话启动注入 messages 数组中的第一条 user message └── 加载 MEMORY.md → 作为 user msg "[System: memory index]\n{content}\n[End]"
三种运行模式 1 2 3 4 5 6 7 8 9 10 11 12 13 python memory_system_example.py demo python memory_system_example.py api-demo python memory_system_example.py chat
模式 2 (api-demo) 是最值得运行的 ——它展示了完整的两个会话生命周期:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 会话 A: 发送 3 条预设的用户消息(角色信息、测试偏好、项目信息) → 控制台实时打印模型生成的每一个 tool call → 可以看到模型自己决定了: · 哪些信息值得保存 · 用什么文件名 · frontmatter 怎么写 · 正文怎么组织 → 最后展示磁盘上生成的所有文件 会话 B: 全新的 messages 数组(模拟新会话) → 加载上一个会话写入的 MEMORY.md → 提问 "What do you remember about me?" → 模型从记忆中回答,不需要用户重复信息
核心洞察 :上下文窗口是 Claude Code 中最宝贵的资源。Claude Code 通过自动压缩、子代理隔离、延迟加载、prompt caching 等机制自动管理它。但用户也可以通过合理组织 CLAUDE.md、善用子代理、及时清理等方式主动优化上下文使用。